Using git, but Properly
"It is easy to shoot your foot off with git, but also easy to revert to a previous foot and merge it with your current leg."
~ Jack William Bell
At ASE, we mandate the use of proper git principles during your project. So much so, that it is reflected in your final grade and is monitored both automatically and with manual reviews. But when is git "proper"? And how can one avoid improper git? That is best shown by example. We will ignore the basics (you should know these at this point in your Bachelor's anyway) and instead focus on the rationale and use of principled git.

Elias Groot
Software Lead, Course Organizer
In a fundamental way, git (or any version control software) serves as a convenient tool to synchronize files between developers. But - without trying to get too abstract - a git repository is not just a syncing mechanism: it tells contributors (and teaching staff) a story about your software. When applied properly, the commit history describes how (and why!) software evolved, branches describe ongoing work that might be added to your project, and tags and releases mark stable points in the lifetime of your project, that can be shared, deployed or rolled back to. Unfortunately, git in itself does not dictate how it is best used, so you need to apply opinionated principles and their derived conventions to streamline your commits, branches and pull requests. This forms the basis of proper git use.
We propose our opinions and conventions and expect you to actively use and practice with them. Even if you don't agree with (all of) them, practicing with them daily during your project will train you to become a better team player while maintaining a clean and easy to follow software development trail. And as you will hopefully see at the end of this tutorial, proper git does not take much time or effort: it is all about defining a clear routine and following it together with your team so that all contributors can enjoy a frictionless git experience.
Commit Often
As you know, the most essential building block of the git history that you are writing is a commit: a set of changed files together with a summary and a description. It is up to the developer to choose how often to commit, how many files to commit at once and how to describe the changes. In other words: a lot of potential to turn your commit history into a total mess.
But worry not, by being opinionated about what commits should look like, one can steer away from a commit monstrosity. The key principle is to commit (and push) often. Not only do frequent commits allow for much more fine-grained rollbacks and checkouts, it also allows your team to work more seamlessly in parallel, by already sharing (parts of) implementations and interfaces that can be used to get started on the next task.
"Duh, simple" you say, and in theory it is. Though, you will often find yourself wanting to push all your changes at once. It can be tempting to just submit "all files for the first deadline" and hit enter, but resist the urge and split up your commits into more fine-grained (and better described) ones. It will improve the team spirit (nobody likes a team member that pushes monolithic commits) but first and foremost, your future self will be grateful - trust us on ths one.
❌ Don't commit monoliths with non-descriptive summaries:
"All changes left on my computer""Week 1 changes""Final deadline submission"
✅ But chunk it up, summarizing the changes conveniently:
"feat: implemented /status API endpoint""fix: index out of range in GetDevice()""chore: typo ("crgo" -> "cargo")"
And we understand: everyone forgets to commit from time to time - sometimes deadlines get the best of you - but think before you push. Is git add . really the way to go? Or can you split up your commit into multiple smaller ones instead? Often you can, and you should.
❌ Don't let your team (and yourself) deal with this:
# commit the bulk
git add .
git commit -m "Done for this week"
git push
✅ But create a clear trail like this:
# create multiple commits from your current changes, for more fine-grained rollbacks
git add api.c api.h
git commit -m "feat: created API interface"
git add README.md
git commit -m "chore: updated README to reflect new interface"
git add .gitignore
git commit -m "fix: excluded .DS_Store from version control (sigh)"
# push all together
git push
The above example illustrates that you don't need to switch to your terminal after every file change. Instead, at the end of your workday, give yourself five minutes to think about the changes that you made and in which small chunks they should be uploaded. Consider it a form of meditation, winding down before you close your laptop. Learn to appreciate a zen yet descriptive commit history.
Writing a Good Commit Message
Above all, commit messages describe the changes or improvements made and nothing else (again, this is harder than it sounds. You will see). Unfortunately, there is no golden rule for a "good" commit message, but by committing often, you can be much more descriptive about the chunk of changes you are uploading. We require the use of Conventional Commits, which in a nutshell means that you must start every commit message with feat:, fix: or chore: depending on the type of change. This requires you to think critically about the nature of the changes and makes it easier for your team member (and us) to understand its impact. Take the time to read up on conventional commits here, they are commonplace in industry and their usage spans further than "just" descriptive messages, like automatically applying semantic versioning to releases and creating auto-generated changelogs.
But besides the description and the impact, a very important question often is why did you make a change? While commit messages can be maximally 72 characters, the description field allows for ample text and hence serves as the perfect place to put your rationale. Use it!
❌ Don't add non-explanatory descriptions:
commit a4ebf50fa818019737ed2d28e21e4d05fee14d18
fix: switched "about" text to <p> tag
I hope the people at ASE are happy with this.
✅ Use the space to explain why the changes are made:
commit a4ebf50fa818019737ed2d28e21e4d05fee14d18
fix: switched "about" text to <p> tag
The about text was rendered too large, and using a <h2> tag wasn't compliant with semantic HTML.
Branch Sensibly
To get it out and over with: do not use different branches to manage different projects. That is what separate repositories are for. Branches should be short-lived, rather dying sooner than later. They reflect different parts of the same puzzle, not different puzzles.
❌ Don't create branches for different projects in one repository:
- github.com/team12/ase-project
/thesis
/code
/presentation
✅ Go for small-scoped, short-lived branches and split up repositories in an organization if necessary:
- github.com/team12/thesis
/feature/introduction
/feature/conclusion - github.com/team12/code
/feature/API-interface
/fix/malloc-OOM - github.com/team12/presentation
/feature/slide-design
/chore/sources
Merge to main often (by using Pull Requests and Code Reviews) but be clear about what main represents: stable code. Code that works, was tested and reviewed. Keep your experimental code in your own branch and delete branches that are not being worked on any more.
Picking a Descriptive Branch Name
Like with clear commit messages, a good branch name goes a long way. Using a descriptive prefix helps your team to quickly differentiate and triage features, bug fixes and documentation changes. Choosing a name that reflects the core change allows for convenient progress tracking, and because you can see the contributors and commits for a specific branch, you can quickly see which milestone needs some love still. This is especially valuable in larger teams, where TODOs are not assigned to individual contributors but just as well holds for any team that has a lot of TODOs and implements them in a high pace (such as at ASE).
❌ Don't name branches after yourself, a point in time, or anything that does not describe the nature of the changes:
- /elias-work
- /deadline-submission
- /wednesday-code
✅ Describe the (proposed) changes and use a category prefix:
- /feature/roverlib-integration
- /fix/missing-fonts
- /docs/readme-installation-steps
You are required to follow our branch naming strategy, which dictates that every branch name should follow the <category>/<reference>/<description> pattern.
- The category can be one of
feature,fix,docs - The reference should be an issue number. You can omit this if you don't use (Github) issues
- The description describes the changes you are proposing
Keep in mind that if you find it hard to write a concise description for your branch, you are not branching sensibly. This is often the case if there are multiple (unrelated) changes made to the same branch. In this case you should branch further and group the changes in a way that makes sense to your team. In the examples above, we already showed how to follow our branch naming strategy, but you can find a cheat sheet here.
Verify and Deliver Continuously
Even though this is not a feature directly in git itself, Continuous Integration and Continuous Deployment (CI/CD) are essential parts in any modern software development workflow. They prevent developers from making the mistake of "it works on my machine" (also known as the localhost fallacy) and allows for automated linting, testing, building, versioning and deploying. We require the use of Github Organizations with Github Actions for ASE, but all major git hosting services support CI/CD in their own way, and specialized services (such as CircleCI and ArgoCD) exist.
If you did not apply yet, you should apply for the Github Student Developer Pack to get Github Pro for free during your studies. It has a lot of perks, among which are free Github Actions minutes you can use for CI and CD actions.
You are required to implement at least one basic CI workflow that is performed on every push or merge to main for at least one repository. A simple workflow is added as an example. Feel free to copy and adjust it to your needs.
name: CI Compile
# Run these checks on a push or PR to main
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
build:
runs-on: ubuntu-22.04
steps:
# Fetch all files in this repository
- name: Checkout Code
uses: actions/checkout@v4
# Set up the C compiler
- name: Install GCC
run: sudo apt-get update && sudo apt-get install -y gcc
# Compile the program with extensive warnings
- name: Compile program.c with warnings
run: |
gcc -o program program.c \
-Wall -Wextra -Werror -pedantic -std=c11 \
-Wshadow -Wformat=2 -Wfloat-equal -Wconversion -Wunreachable-code \
-Wnull-dereference -Wuninitialized -Wdouble-promotion -Wformat-security \
-fanalyzer
This workflow clones the code in your repository to an isolated environment (on Github servers) and does a clean installation and compilation. It shows you if any of these steps failed or rewards you with a checkmark if all is fine. There really is no reason to not use CI workflows unless you like to stay in the dark about the state of your code.
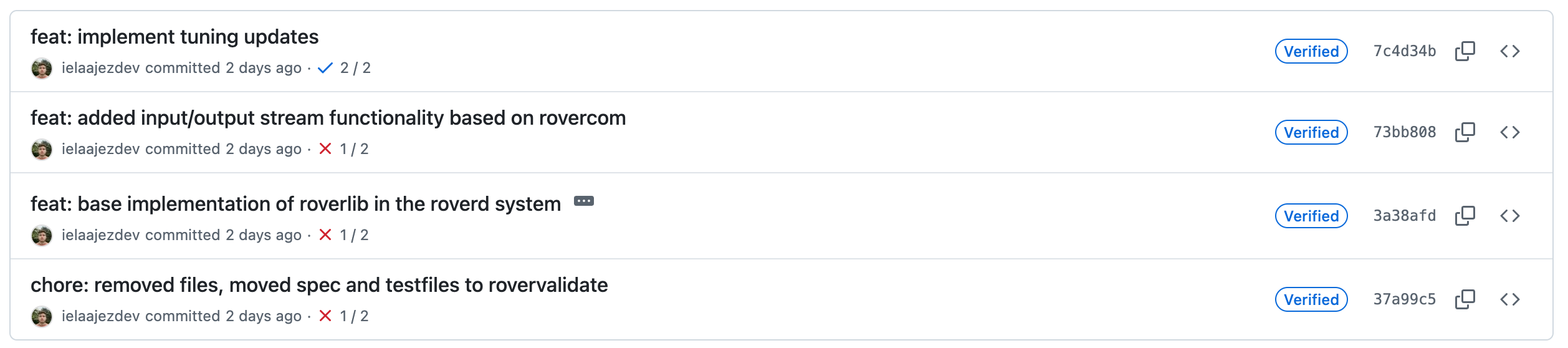
Compiling is just one of the many tasks you can automate using CI/CD workflows. During my studies, I always used this to make sure that I only submitted code that could be compiled for programming assignments but the possibilities span way beyond that. Other examples (that we also use at ASE) are:
- Lint code on every push, enforcing the same code style for everyone
- Optionally auto fix issues if possible, like removing indentation or using single quotes instead of double quotes
- Run language-specific automated tests and check coverage
- Generate automated release notes and CHANGELOG files
- Build semantically versioned releases automatically and upload them to artifact hosting services like Github Container Registry, Docker Hub or the ASE downloads manager
- Also depends on the Conventional Commit structure discussed earlier
- Enforce Conventional Commits
- Synchronize repositories and set up infrastructure (like this docs site)
You are expected to tailor your CI workflow to your choice of programming language, build tools and dependencies. Github Actions can be tricky to get right, so make sure to ask an on-site supervisor for help when you are stuck. Finally, these workflows are supposed to help you. Do not add them at the last moment to satisfy the ASE requirements but take a moment to set them up while initializing a repository. It will give much peace of mind during the project. You can find a get-started guide here.
Protect your Code
As mentioned before, be clear about what the main branch represents: stable, tested and reviewed code. An optional but much encouraged way to enforce this is by setting up Branch Protection Rules. Again, this is tailored to Github specifically, but you will find them with all the major git providers.
A branch protection rule prevents any direct pushes to main and, even better, enforces that selected CI workflows pass before a branch can be merged to main. Depending on the extensiveness of your workflows, this takes a lot of stress away at submission time.
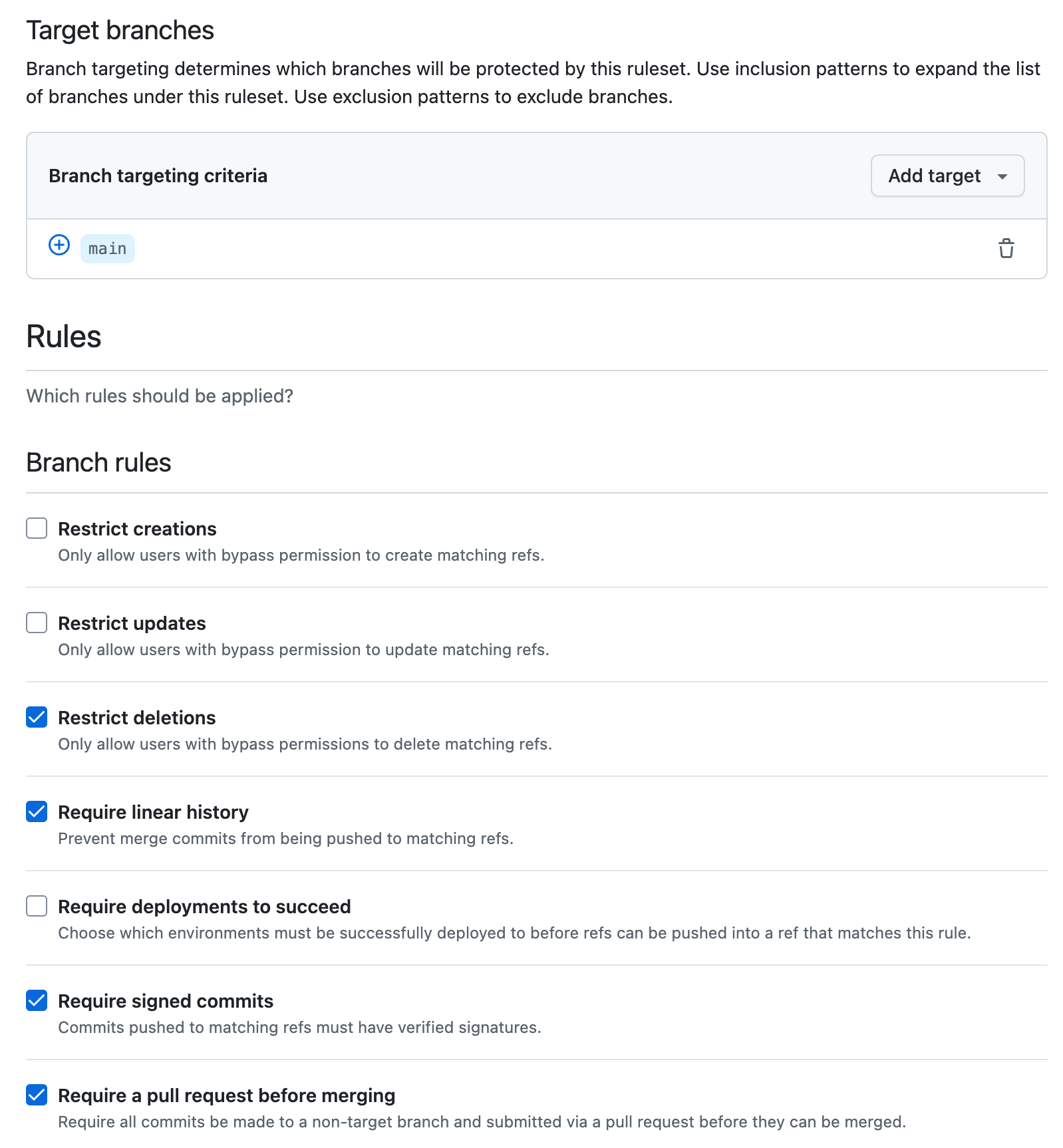
As shown above, additional rules can be enabled to force git usage beyond the conventions discussed in this tutorial. If you are interested in setting this up, you can find a quick start guide on branch protection rules here.
"Pushing" Even Further
In this tutorial we just scratched the surface of what one can (and should) do with git. I am a big fan of a tight git-integrated workflow (often called gitops) so if you want to streamline even further, here are some interesting ideas that we also apply at ASE:
- Create reusable workflows, that can be referenced in any repository, like our actions
- Create custom (Docker) images that can be used for efficient caching and ready to go development containers
- Use template repositories to quickly get started without writing any boilerplate
- Use periodic actions to sync documentation from multiple repositories
- Use
metato treat all separate repositories as a monorepo- At the point of writing, we have 64 ASE repositories, so this became a necessity quickly
But even ignoring all of this, the best way to bring the examples in this tutorial to life is by just doing. Fortunately, the ASE project serves as the perfect opportunity for that. It will not always be straightforward, but continuing to use (and with that, improve) your git usage will almost certainly improve the way you work on team projects later, and I do not think that it needs mentioning how valuable this will be throughout your career.